记录一下忘记了过来查
Ubuntu和CentOS
Ubuntu系统和CentOS都是Linux系统
CentOS可以直接安装换系统,也可以通过虚拟机安装得到
Ubuntu可以在电脑上同时使用Linux和Windows系统
Linux系统: “所见皆文件”
- 方便性:使计算机系统易于使用
- 有效性:以更有效的方式使用计算机系统资源
- 扩展性:方便用户有效开发、测试和引进新功能
- 开放性:所谓开放性,是指系统能遵循世界标准规范,特别是遵循开放系统互连OSI 国际标准。
Linux系统目录:
bin:存放二进制可执行文件
boot:存放开机启动程序
dev:存放设备文件: 字符设备、块设备
home:存放普通用户
etc:用户信息和系统配置文件 passwd、group
lib:库文件:libc.so.6
root:管理员宿主目录(家目录)
usr:用户资源管理目录
Linux系统文件类型: 7/8 种
普通文件:-
目录文件:d
字符设备文件:c
块设备文件:b
软连接:l
管道文件:p
套接字:s
未知文件。
Linux系统文件和目录权限
文件权限细分
权限细节总共分为10个槽位
/MyBlog/source/_posts/C-%E5%AD%A6%E4%B9%A0/1701699914895.png)
举例:drwxr-xr-x,表示:
•这是一个文件夹,首字母d表示
•所属用户(右上角图序号2)的权限是:有r有w有x,rwx
•所属用户组(右上角图序号3)的权限是:有r无w有x,r-x (-表示无此
权限)
•其它用户的权限是:有r无w有x,r-x
文件类型 所有者的读写可视型 同组用户的读写可实行 其他的读写可实行
r是读 数字是4
w是写 2
x是执行 1
数字的细节如下:r记为4,w记为2,x记为1,可以有:
•0:无任何权限, 即 —
•1:仅有x权限, 即 –x
•2:仅有w权限 即 -w-
•3:有w和x权限 即 -wx
•4:仅有r权限 即 r–
•5:有r和x权限 即 r-x
•6:有r和w权限 即 rw-
•7:有全部权限 即 rwx
举例: 751所表示的权限为: rwx(7) r-x(5) –x(1)
默认读写读写读写 -rw-rw-rw 其文件权限掩码为666
原来的掩码通过umask指令得到 一般是0002转二进制就是0010 即只有其他用户有写权限
想要修改为最大权限的话,就是0666-0002=0664,实际上虽然可以这样计算,但其实是转二进制之后按位与非 06666 & ~0002 = 0664
而对于文件夹的命令 最大权限是0777 umask是0002,按照上述计算,得到0775
想要直接设置文件权限的话,在终端输入umask 0,再运行umask查看文件权限,会得到0000
软连接:快捷方式
为保证软连接可以任意搬移, 创建时务必对源文件使用 绝对路径。
硬链接:
ln file file.hard
操作系统给每一个文件赋予唯一的 inode,当有相同inode的文件存在时,彼此同步。
删除时,只将硬链接计数减一。减为0时,inode 被释放。
创建用户:
sudo adduser 新用户名 --- useradd
修改文件所属用户:
sudo chown 新用户名 待修改文件。
sudo chown wangwu a.c
删除用户:
sudo deluser 用户名
创建用户组:
sudo addgroup 新组名
修改文件所属用户组:
sudo chgrp 新用户组名 待修改文件。
sudo chgrp g88 a.c
删除组:
sudo delgroup 用户组名
使用chown 一次修改所有者和所属组:
sudo chown 所有者:所属组 待操作文件。
一些查看和操作命令
1 | pwd 查看当前文件目录 |
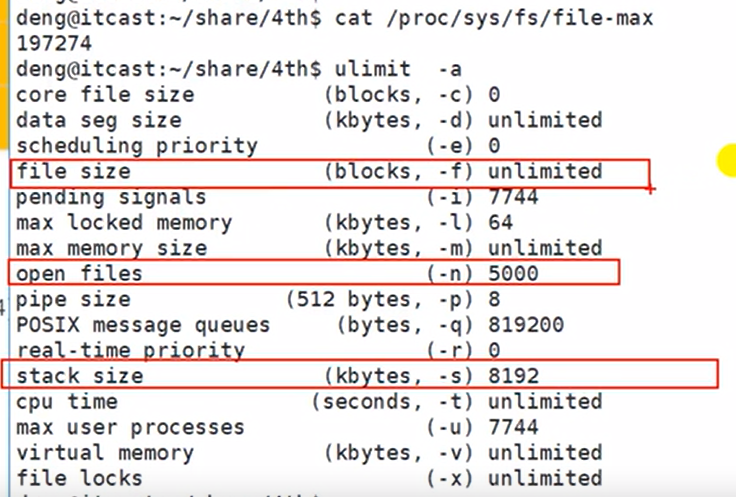
当前系统默认打开19万个文件,但是栈限制打开500个
堆每个指令栈8192bit 8k
bit 位
byte 字节
1byte = 8 bit
1K = 1024 bit = 2^10 bit
1M = 2^10 K
1G = 2^10 M
想要修改文件打开最大个数 就ultimate -n 1024
如果想修改别的 可以看括号里的值 后面加上自己想改的数字
find命令:找文件
-type 按文件类型搜索 d/p/s/c/b/l/ f:文件
-name 按文件名搜索
find ./ -name "*file*.jpg"
-maxdepth 指定搜索深度。应作为第一个参数出现。
find ./ -maxdepth 1 -name "*file*.jpg"
-size 按文件大小搜索. 单位:k、M、G
find /home/itcast -size +20M -size -50M
-atime、mtime、ctime 天 amin、mmin、cmin 分钟。
-exec:将find搜索的结果集执行某一指定命令。
find /usr/ -name '*tmp*' -exec ls -ld {} \;
-ok: 以交互式的方式 将find搜索的结果集执行某一指定命令
1 | find ../ -size +21k -size -23k exec ls -l {} \; |
管道运算符 |
1 | find ./ -maxdepth -type f -exec ls -l {} \; |
两者都是找到文件之后执行
但是exec是所有命令一股脑执行
xargs当结果比较大的时候分开处理,分区,处理完第一片再处理第二片,但是对于文件名中有空格的文件会误拆分、
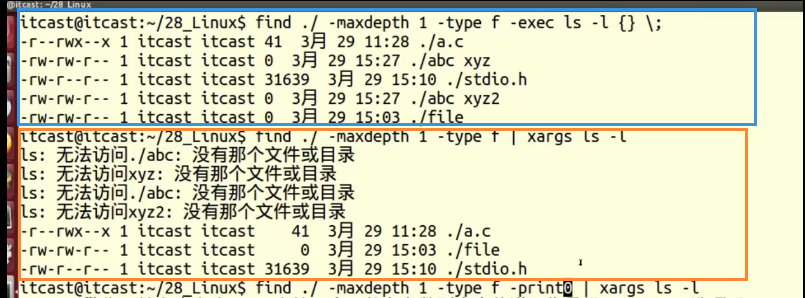
此时需要用
1 | find ./ -maxdepth -type f -print0| -xarg -0 ls -l |
第一个-print是find的参数
xargs拆分原来是用空格作为区分依据的现在改成0
-xargs:将find搜索的结果集执行某一指定命令。 当结果集数量过大时,可以分片映射。
find /usr/ -name ‘tmp‘ | xargs ls -ld
-print0:
find /usr/ -name ‘tmp‘ -print0 | xargs -0 ls -ld
awk 拆分
awk 行拆分
sed 列拆分
很复杂暂时不看
grep命令:找文件内容
grep -r 'copy' ./ -n
-n参数::显示行号
ps aux | grep 'cupsd' -- 检索进程结果集。
touch 创建文件
1 | touch 'abd.h' |
man命令
1 | man fopen |
查看fopen的说明 相当于help
软件安装:
CentOS的软件安装工具不是apt-get ,而是yum,Ubuntu使用apt-get
1 | 1. 联网 |
软件源:
一般是国内的服务器从国外的服务器下载安装软件,然后用户从国内的服务器上下载软件安装,在下载的同时会更新国内服务器的软件列表(2)
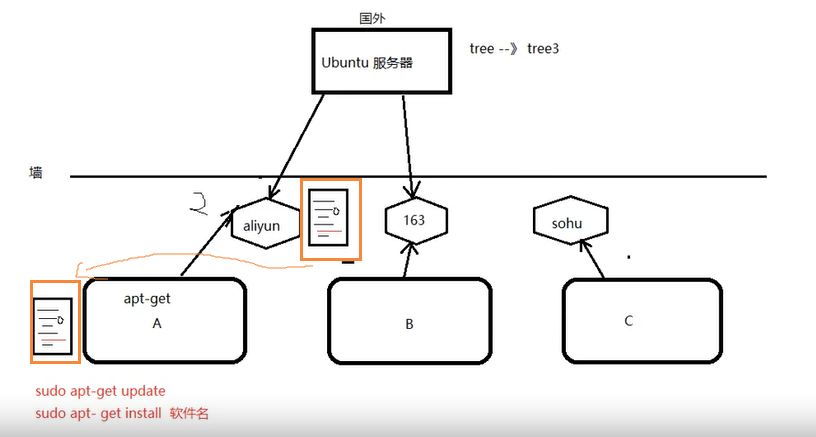
4. 卸载 sudo apt-get/yum remove 软件名
5. 使用软件包(.deb) 安装: sudo dpkg -i 安装包名。
这是在线安装,同时也支持离线安装
/MyBlog/source/_posts/Linux%E7%B3%BB%E7%BB%9F%E7%BC%96%E7%A8%8B/1701952056166.png)
Linux和fred bsd
Linux 两大分支
参考的这个 https://www.cnblogs.com/garinzhang/p/diff_between_yum_apt-get_in_linux.html
RedHat系列:Redhat、Centos、Fedora等
Debian系列:Debian、Ubuntu等
RedHat 系列
- 常见的安装包格式 rpm包,安装rpm包的命令是“rpm -参数”
- 包管理工具 yum
- 支持tar包
Debian系列
- 常见的安装包格式 deb包,安装deb包的命令是“dpkg -参数”
- 包管理工具 apt-get
- 支持tar包
.deb 安装包 相当于.exe文件
安装安装包
1 | sudo dpkg -i sl_3.03-17_amd64.deb |
删除安装包
1 | sudo dpkg -r sl_3.03-17_amd64.deb |
-r是递归的意思
源码包安装:
1 | 1.解压缩源代码包 |
PS:
安装的时候yum出错了,先是报这个错
1 | failure: repodata/repomd.xml from dag: [Errno 256] No more mirrors to try. |
再是报这个错
1 | Error: File contains parsing errors: file:///etc/yum.repos.d/docker-ce.repo |
最后是按照这个帖子记录的解决的
1 | https://blog.csdn.net/weixin_39137153/article/details/125454385 |
看不懂,但是解决了。记录一下后面知道的多了再回来看看
按照这个链接安装rar
1 | https://blog.csdn.net/qq_21875331/article/details/110948805 |
但是在线链接还是不行
改离线安装
压缩包
tar压缩:
1. tar -zcvf 要生成的压缩包名 压缩材料。
z: 以zip的方式进行压缩
c: 创建打包文件
v: 显示压缩过程
f: file 指定档案文件名称
t: 列出档案中的文件
x:解压
tar zcvf test.tar.gz file1 dir2 使用 gzip方式压缩。
也可以 tar zcvf test.mp3 file1 dir2 会成功,但是不利于我们文件管理
tar.gz表示用tar命令以gzip的方式进行压缩
1 | tar jcvf test.tar.gz file1 dir2 使用 bzip2方式压缩。 这个跟gzip压缩方式一样,也不能压缩目录,也不能同时压缩多个文件? 明明吧这些文件压缩到了test的压缩包里 |
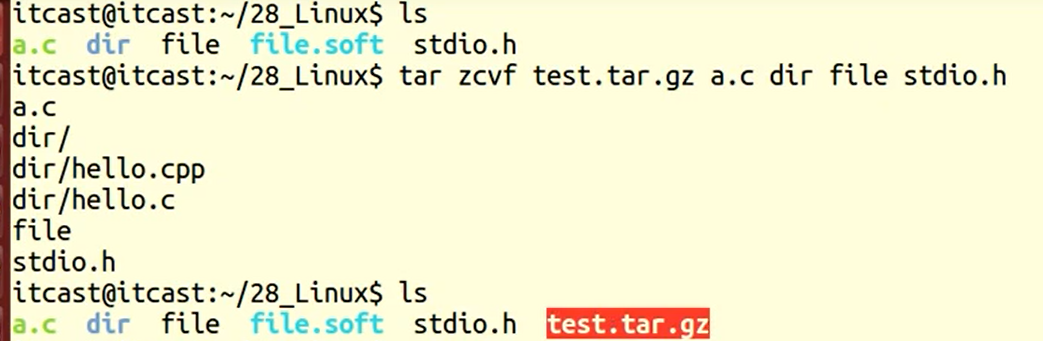
tar解压:
将 压缩命令中的 c --> x
tar zxvf test.tar.gz 使用 gzip方式解压缩。
tar jxvf test.tar.gz 使用 bzip2方式解压缩。
rar压缩:
rar a -r 压缩包名(带.rar后缀) 压缩材料。
rar a -r testrar.rar stdio.h test2.mp3
rar解压:
unrar x 压缩包名(带.rar后缀)
zip压缩:
zip -r 压缩包名(带.zip后缀) 压缩材料。
zip -r testzip.zip dir stdio.h test2.mp3
zip解压:
unzip 压缩包名(带.zip后缀)
unzip testzip.zip
GCC编译器
gcc -E S c
Hello.c .i .s .o .out
1 | deng@itcast:~/share/3rd/1gcc$ ls 1hello.c |
或者直接将源文件生成一个可以执行文件
deng@itcast:
/share/3rd/1gcc$ gcc 1hello.c -o 1hello deng@itcast:/share/3rd/1gcc$ ./1hello hello itcast
如果不指定输出文件名字, gcc编译器会生成一个默认的可以执行a.out
deng@itcast:
/share/3rd/1gcc$ gcc 1hello.c/share/3rd/1gcc$ ls 1hello 1hello.c 1hello.i 1hello.o 1hello.s a.out deng@itcast:~/share/3rd/1gcc$ ./a.out
deng@itcast:
hello itcast
gcc常用选项
| 选项 | 作用 |
|---|---|
| -o file | 指定生成的输出文件名为file |
| -E | 只进行预处理 |
| -S(大写) | 只进行预处理和编译 |
| -c(小写) | 只进行预处理、编译和汇编 |
| -v / –version | 查看gcc版本号 |
| -g | 包含调试信息 |
| -On n=0~3 | 编译优化,n越大优化得越多 |
| -Wall | 提示更多警告信息 |
| -D | 编译时定义宏 |
测试程序(-D选项):
deng@itcast:~/test$ gcc 2test.c -DSIZE=10
deng@itcast:~/test$ ./a.out
SIZE: 10
1 | #include <stdio.h> |
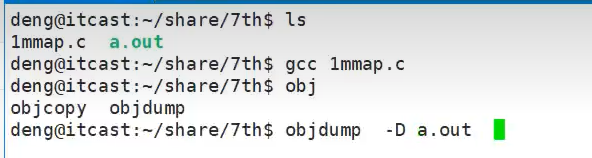
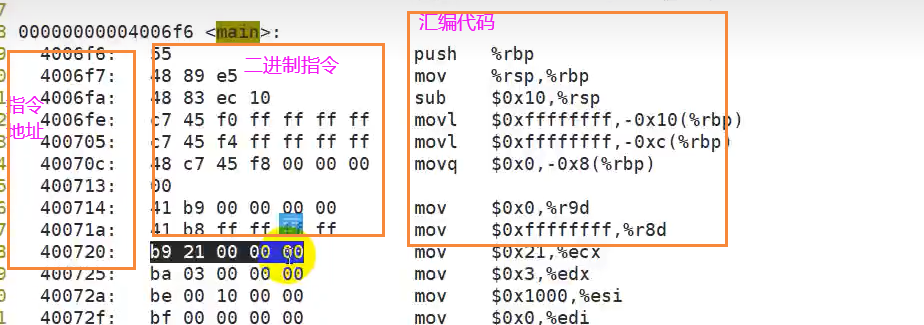
objdump反汇编
objdump -D a.out
静态库和动态库
在经过编译之后的一些可执行程序中的某些代码是高度重复的,可以先得到指令之后编号索引压缩打包之后放在那里,避免反复编译,实现代码重用(听起来像java的编译方式)
但是这些库不能单独执行,只能配合其他程序执行
静态库
libhccl.a
lib:前缀 , hccl:库名 ,.a:后缀
制作过程:
步骤1:将c源文件生成对应的.o文件
gcc -c add.c -o add.o
gcc -c sub.c -o sub.o
gcc -c mul.c -o mul.o
gcc -c div.c -o div.o
步骤2:使用打包工具ar将准备好的.o文件打包为.a文件 libtest.a
ar -rcs libtest.a add.o sub.o mul.o div.o
其中ar -rcs
- r更新
- c创建
- s建立索引
使用
写add.c,sub.c,mul.c,div.c是需要头文件的,假设头文件是head.h,这四个文件编译生成的四个.o文件压缩成libhccl.a,这些文件都在 ./ 文件目录里,需要编译的文件是test.c
原来使用gcc编译文件是
gcc test.c -o test
使用静态库变成了
gcc -L./ -I./ -lhccl -o test
参数说明:
- -L:表示要连接的库所在目录
- -I./: I(大写i) 表示指定头文件的目录为当前目录
- -l(小写L):指定链接时需要的库,去掉前缀和后缀
静态链接:由链接器在链接时将库的内容加入到可执行程序中。 gcc -static test.c -o test_static
缺点:
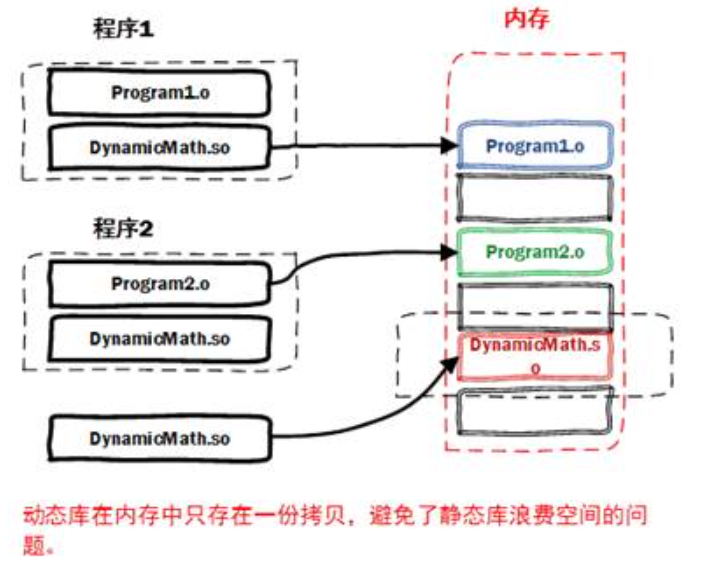
动态库
动态库可以解决静态库的上述问题
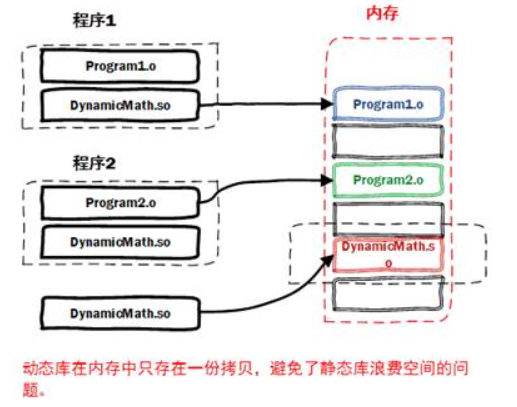
libhccl.so
- 前缀:lib
- 库名称:自己定义即可
- 后缀:.so
制作过程
步骤一:生成目标文件,此时要加编译选项:-fPIC(fpic)
deng@itcast:~/test/5share_lib$ gcc -fPIC -c add.c
deng@itcast:~/test/5share_lib$ gcc -fPIC -c sub.c
deng@itcast:~/test/5share_lib$ gcc -fPIC -c mul.c
deng@itcast:~/test/5share_lib$ gcc -fPIC -c div.c
参数:-fPIC 创建与地址无关的编译程序(pic,position independent code),是为了能够在多个应用程序间共享。
步骤二:生成共享库,此时要加链接器选项: -shared(指定生成动态链接库)
deng@itcast:~/test/5share_lib$ gcc -shared add.o sub.o mul.o div.o -o libtest.so
步骤三: 通过nm命令查看对应的函数
deng@itcast:~/test/5share_lib$ nm libtest.so | grep add
00000000000006b0 T add
deng@itcast:~/test/5share_lib$ nm libtest.so | grep sub
00000000000006c4 T sub
(一个命令20 bit?)
ldd查看可执行文件的依赖的动态库
deng@itcast:~/share/3rd/2share_test$ ldd test
linux-vdso.so.1 => (0x00007ffcf89d4000) libtest.so => /lib/libtest.so (0x00007f81b5612000) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f81b5248000) /lib64/ld-linux-x86-64.so.2 (0x00005562d0cff000)
动态库测试
引用动态库编译成可执行文件(跟静态库方式一样)
deng@itcast:~/test/6share_test$ gcc test.c -L. -I. -ltest (-I. 大写i -ltest 小写L)
然后运行:./a.out,发现竟然报错了!!!

- 当系统加载可执行代码时候,能够知道其所依赖的库的名字,但是还需要知道绝对路径。此时就需要系统动态载入器(dynamic linker/loader)。
- 对于elf格式的可执行程序,是由ld-linux.so*来完成的,它先后搜索elf文件的 DT_RPATH段 — 环境变量LD_LIBRARY_PATH — /etc/ld.so.cache文件列表 — /lib/, /usr/lib目录找到库文件后将其载入内存。
3)如何让系统找到动态库
- 拷贝自己制作的共享库到/lib或者/usr/lib(不能是/lib64目录)
- 临时设置LD_LIBRARY_PATH:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:库路径
永久设置,把export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:库路径,设置到~/.bashrc或者 /etc/profile文件中
deng@itcast:~/share/3rd/2share_test$ vim ~/.bashrc
最后一行添加如下内容:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/deng/share/3rd/2share_test
使环境变量生效
deng@itcast:
/share/3rd/2share_test$ source ~/.bashrc deng@itcast:/share/3rd/2share_test$ ./test
a + b = 20 a - b = 10将其添加到 /etc/ld.so.conf文件中
编辑/etc/ld.so.conf文件,加入库文件所在目录的路径
运行sudo ldconfig -v,该命令会重建/etc/ld.so.cache文件
deng@itcast:~/share/3rd/2share_test$ sudo vim /etc/ld.so.conf
文件最后添加动态库路径(绝对路径)

使生效
deng@itcast:~/share/3rd/2share_test$ sudo ldconfig -v
使用符号链接, 但是一定要使用绝对路径
deng@itcast:~/test/6share_test$ sudo ln -s /home/deng/test/6share_test/libtest.so /lib/libtest.so
动态链接:连接器在链接时仅仅建立与所需库函数的之间的链接关系,在程序运行时才将所需资源调入可执行程序。 gcc test.c -o test_share
GDB调试器
gdb a.out 进入调试
b main 设置断点
run 开始运行
n 下一步
quit 退出
makefile
目标: 依赖1 依赖2 …依赖n
命令1
命令2
…
命令n

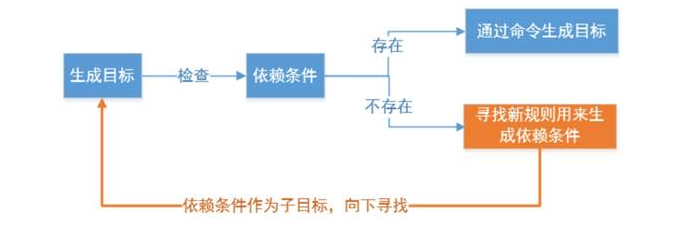
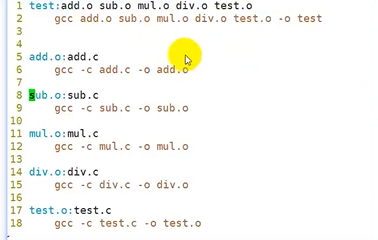
以上图为例,make 的默认目标是test,但是test的依赖都没有,所以去根据对应的规则寻找对应的依赖,所以先生成加减乘除的.o文件作为依赖,再根据这些依赖生成一个可执行文件
先vim 1.h
1 | test: |
之后保存退出
再 make -f 1.mk1就会出现 echo “hello world”
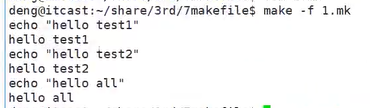
执行下面这段代码 先执行test1,再执行test2,再执行test
1 | test:test1 test2 |
rm -rf a.out强制递归删除a.out文件
最简单的makefile文件
先在含有test.c add.c sub.c mul.c div.c的文件夹里执行
vim MakeFile命令
1 | test:test.c add.c sub.c mul.c div.c |
缺点:效率低,修改一个文件,所有文件会被全部编译
** 第二个版本Makefile**
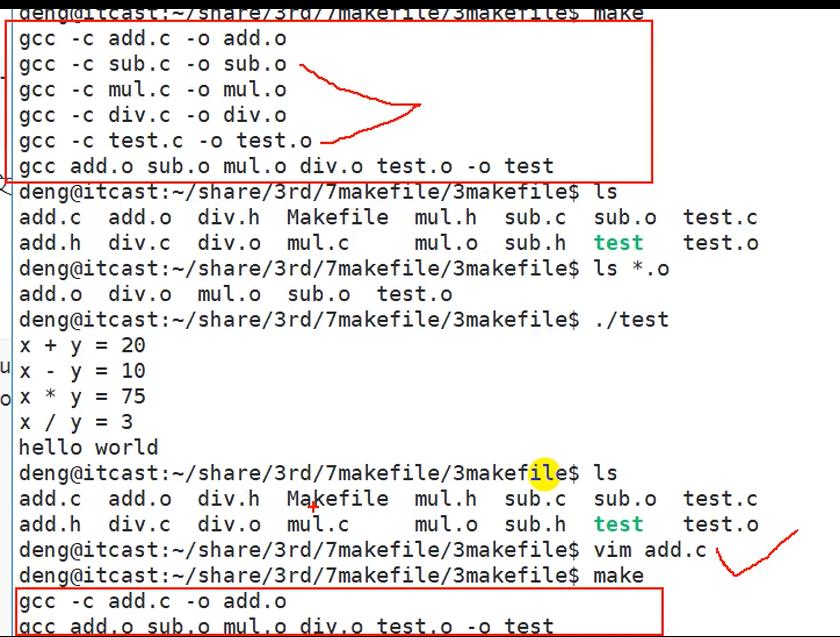
1 | test:test.o add.o sub.o mul.o div.o |
1 |
|
自动变量
1 |
|
模式规则
1 | 模式规则示例: |
Makefile第三个版本:
1 | OBJS=test.o add.o sub.o mul.o div.o |
make -n 测试
系统调用
CPU可以运行在内核态或者用户态,想要切换到内核态通过软件中断

系统调用是内核给用户执行程序的接口可以调用系统内核的服务,比如获取时间,文件读写,但是是一个通道,不能执行其他的
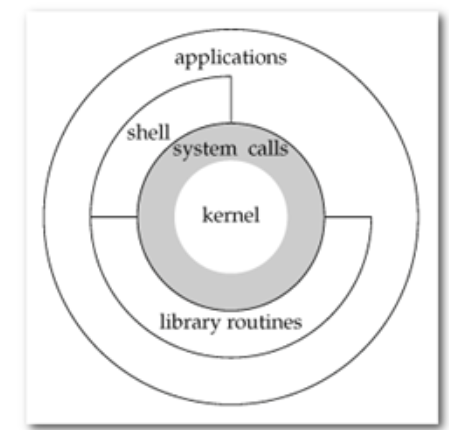
system calls是系统调用,library routines是库函数
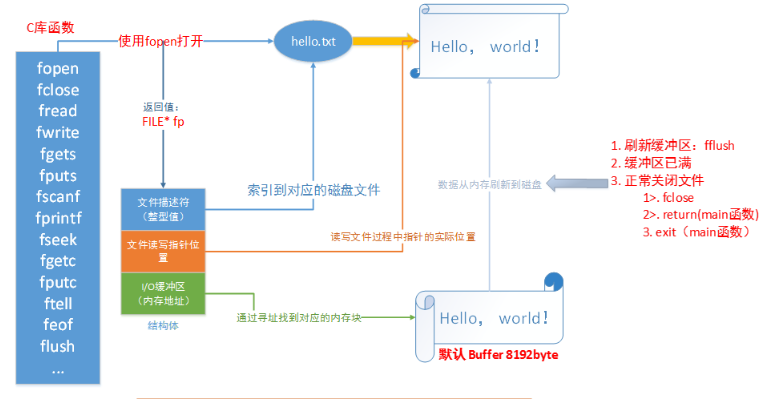
在系统调用时,涉及到程序的部分变量从磁盘进入内存,其中在进入内存的过程中由于磁盘(机械硬盘)和内存的读写速度不一致,中间还有一个缓存
缓存还有另一个作用:提高磁盘访问的速度
程序运行时内存需要不断从磁盘中读取数据,多次读取的数据必然会有重复,所以需要一个角色负责存储读取频率高的数据,这即是缓存,磁盘的缓存叫做磁盘缓存。
磁盘缓存指的是把从磁盘中读出的数据存储到内存中的方式,这样一来,当接下来需要读取相同的内容时,就不会再通过实际的磁盘,而是通过磁盘缓存来读取。磁盘缓存大大提高了磁盘访问的速度。
根据读写速度。寄存器>一级缓存>二级缓存>三级缓存>内存>硬盘
区别:
1、内存是一种高速,造价昂贵的存储设备;而磁盘速度较慢、造价低廉。
2、内存属于内部存储设备,磁盘属于外部存储设备。
3、内存是通过电流来实现存储;磁盘是通过磁记录来实现存储。所以电脑断电后,内存中的数据会丢失,而磁盘中的数据可以长久保留。
虚拟内存(磁盘的一部分)
虚拟内存是指把磁盘的一部分作为假想内存来使用。虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个完整的地址空间),但是实际上,它通常被分割成多个物理碎片,还有部分存储在外部磁盘管理器上,必要时进行数据交换。
计算机中的程序都要通过内存来运行,如果程序占用内存很大,就会将内存空间消耗殆尽。为了解决这个问题,WINDOWS 操作系统运用了虚拟内存技术,通过拿出一部分硬盘来当作内存使用,来保证程序耗尽内存仍然有可以存储的空间。虚拟内存在硬盘上的存在形式就是PAGEFILE.SYS 这个页面文件。
磁盘的物理结构
磁盘的物理结构指的是其存储数据的形式。磁盘是通过其物理表面划分成多个空间来使用的。划分的方式有两种:可变长方式和扇区方式。前者是将物理结构划分成长度可变的空间,后者是将磁盘结构划分为固定长度的空间。windows所使用的是扇区的方式。扇区中,把磁盘表面分成若干个同心圆的空间的线就是磁道。把磁道按照固定大小的存储空间划分而成的就是扇区。扇区是磁盘进行物理读写的最小单位。windows中,一般一个扇区512个字节。
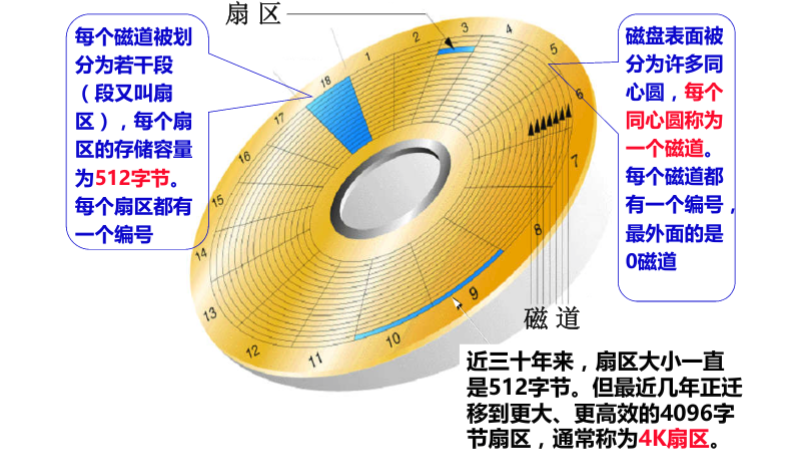
磁盘又通常是由一些旋转着的金属碟片和一个装在步进马达上的读写头组成的。读/写头同一时刻只能出现在一个地方,然后它必须“寻址”到另外一个位置来执行另一次读写操作。所以就有了寻址的耗时,此外还有旋回耗时,读写头需要等待碟片上的目标数据“旋转到位”才能进行操作。(暂定)
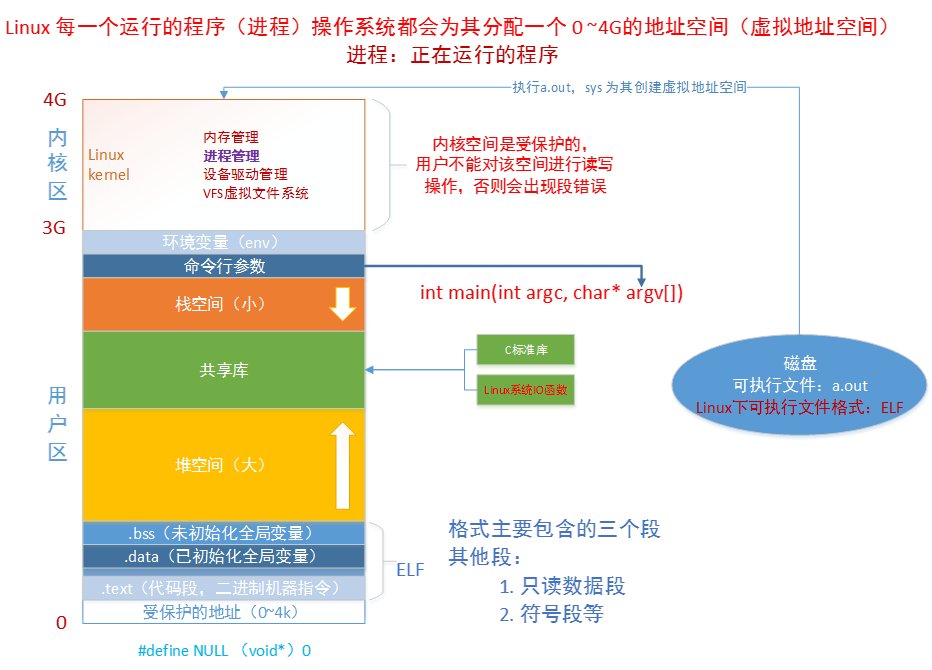
虚拟地址空间
32位机器,该地址空间位4G
2^32 = 2^22K = 2^12M = 2^2G =4G
环境变量包括系统路径等
命令行参数类似于args,options
栈空间存储函数变量
共享库是共享存储映射,内存和文件的通信方式 mmap
堆空间存放局部变量
.bss #define epoch
.data #define epoch 100
.test 写的程序编译得到二进制
在进程里平时所说的指针变量,保存的就是虚拟地址。当应用程序使用虚拟地址访问内存时,处理器(CPU)会将其转化成物理地址(MMU)。
MMU:将虚拟的地址转化为物理地址。
这样做的好处在于:
- 进程隔离,更好的保护系统安全运行
- 屏蔽物理差异带来的麻烦,方便操作系统和编译器安排进程地址
错误处理
1 |
|
当编译遇到报错时,缺少包含的头文件
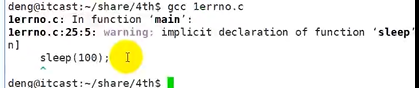
看一下sleep函数的用法
man 2 sleep

man 3 sleep

文件操作
- (空过去)
多进程
ps
进程是一个具有一定独立功能的程序,它是操作系统动态执行的基本单元。
ps命令可以查看进程的详细状况,常用选项(选项可以不加“-”)如下:
| 选项 | 含义 |
|---|---|
| -a | 显示终端上的所有进程,包括其他用户的进程 |
| -u | 显示进程的详细状态 |
| -x | 显示没有控制终端的进程 |
| -w | 显示加宽,以便显示更多的信息 |
| -r | 只显示正在运行的进程 |
ps aux
ps ef
ps -a
只查看后台进程(没有占用终端一直在后台进行)使用jobs命令查看

查看到进程对应的PID之后
比如查找火狐的进程号是35909
ps -Lf 35909 就可以查看这个程序的线程池
父子进程
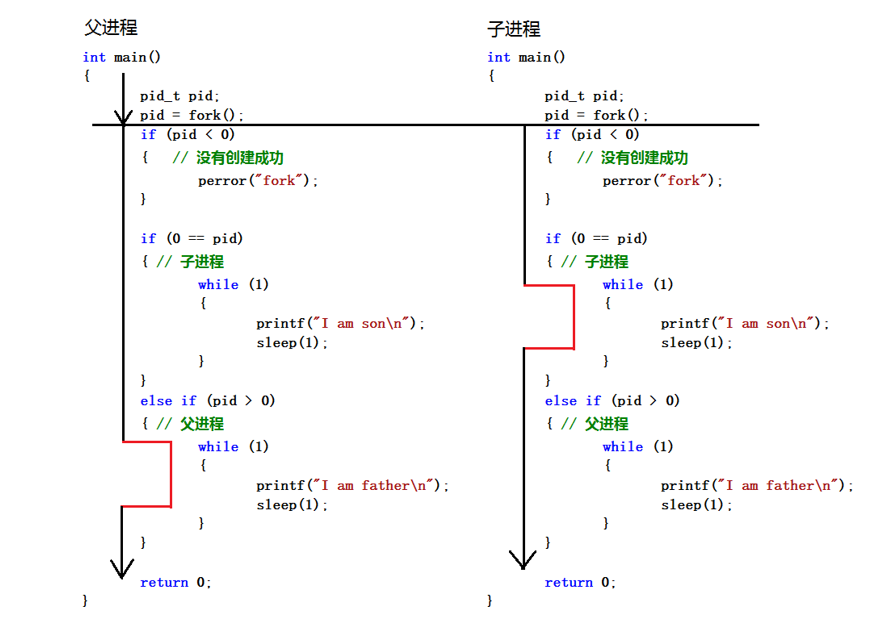
函数
如果是父进程,fork返回进程号+1(子进程pid),getpid返回其进程号
如果是子进程,fork返回0,getpid返回父进程号+1(子进程pid)
1 | int main() |
/MyBlog/source/_posts/Linux%E7%B3%BB%E7%BB%9F%E7%BC%96%E7%A8%8B/1704250319831.png)
子进程是通过fork()函数从父进程复制而来的,包括栈空间。尽管变量b是在main()函数中定义的局部变量,但在子进程中,fork()函数会复制父进程的栈空间,包括变量b。因此,在子进程中,变量b的地址与父进程中的变量b的地址相同。但是这是在两个栈中的相同位置的两个地址,即使b在子进程中的值发生改动,他的地址也不会变
读时共享 写时拷贝
对于全局变量a,我在没有改动它时,他是读时共享的,也就是它只有一个在父进程中的地址,但我对他进行改动时,他会在子进程中创建一个相同的地址,a的地址不管创建没创建它的地址显示出来都是一样的,但是值不一样
1 | int main() |
资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。
如果父子进程变量都没有改动(没有num=11),那么只有读时共享,两者共用一个变量。如果num有变动,那么进行写时拷贝,两者分别拥有一个num
1 |
|
可以通过valgrind命令查看不同进程的释放和分配
1 |
|
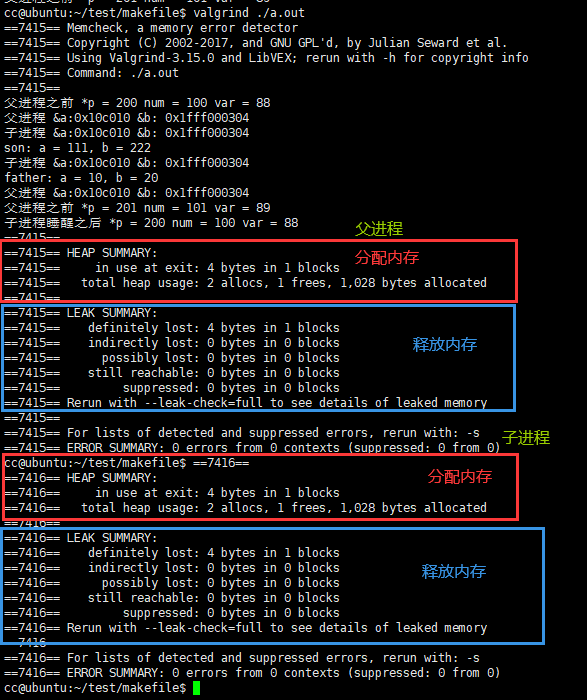
可以看到有内存泄露
gdb调试
- set follow-fork-mode child 设置gdb在fork之后跟踪子进程。
- set follow-fork-mode parent 设置跟踪父进程(默认)。
- 注意,一定要在fork函数调用之前设置才有效。不加默认调试子进程
gdb a.out之后run
set follow-fork-mode child
wait
1 | int status = 1; |
exit
1 | exit |
孤儿进程
父进程停止,子进程依然在进行,一般会被另一个进程收养,在终端操作是1号进程,在图形界面操作是一个pid不确定但是名为upstart进程
僵尸进程
子进程结束了,父进程没有回收其资源
查看是否有僵尸进程 ps aux | grep z
这样可能搜不到,查看一下是否还有gcc生成的a.out 有僵尸进程在运行ps aux | grep a.out

把所有是a.out都杀死 killall a.out
僵尸进程已经是死的,不能被杀死,但是杀死其父进程或者父进程自动退出相当于杀死了僵尸
1 | int main(void) |
进程替换

进程间通讯
目的:数据传输 资源共享 通知事件 进程控制
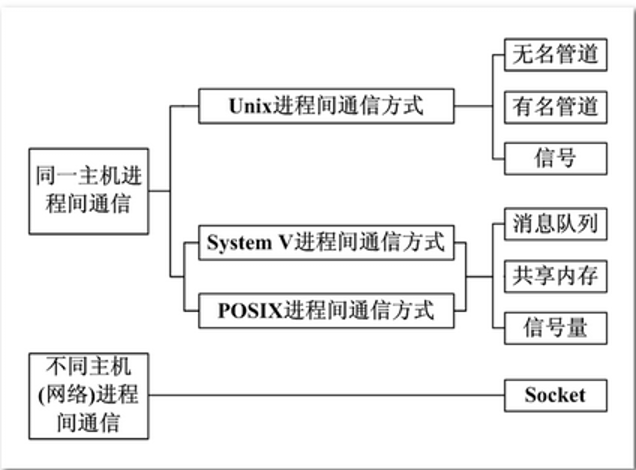
无名管道
半双工,同一时刻只能往同一方向;只能在父子兄弟进程之间使用;不是普通 的文件不属于文件系统,只在内存中;先入先出
pipe
1 | int main() |
管道的读写特点:
- 如果读端和写端都开着
- 如果写端不填进东西,读端一直读,读到管道里没有东西会堵塞;
- 如果读端不读出东西,管道被填满了,管道堵塞;
- 如果读端关闭写端开着
- 写进程在写端运行的时候会收到一个信号然后退出
- 如果读端关闭写端开着
- 读进程读取全部的内容,然后返回0
ulimit -a 查看管道缓冲区大小
一般为4k 512个字节,8块,2^9*8=2^10*4=4k
设置为非阻塞的方法
设置方法:
1 | //获取原来的flags |
1 | int flags = fcntl(fd[0], F_GETFL); |
1 | // 设置新的flags |
1 | flag |= O_NONBLOCK; |
1 | // flags = flags | O_NONBLOCK; |
1 | fcntl(fd[0], F_SETFL, flags); |
结论: 如果写端没有关闭,读端设置为非阻塞, 如果没有数据,直接返回-1。
有名管道
FIFO文件
pipe不在文件系统中只在内存中,但是FIFO在文件系统中作为文件存在,但是其内容放在内存中;不止是有血缘的进程,也可以通信与不相关的进程
在终端中输入以下命令
mkfifo fifo1(fifo1是创建的管道名称)
有名管道的读和写是在两个文件中调用的,一个文件专门读,一个文件写,运行也是要gcc write.c -o write之后./write
(应该是错了待改)
就是错的傻逼玩意
1 |
|
管道的读写特点:
- 一个为只读而打开一个管道的进程会阻塞直到另外一个进程为只写打开该管道
2)一个为只写而打开一个管道的进程会阻塞直到另外一个进程为只读打开该管道
如果读端和写端都开着
- 如果写端不填进东西,读端一直读,读到管道里没有东西会堵塞;
- 如果读端不读出东西,管道被填满了,管道堵塞;
如果读端关闭写端开着
- 写进程在写端运行的时候会收到一个信号然后退出
如果读端关闭写端开着
- 读进程读取全部的内容,然后返回0
读管道:
Ø 管道中有数据,read返回实际读到的字节数。
Ø 管道中无数据:
u 管道写端被全部关闭,read返回0 (相当于读到文件结尾)
u 写端没有全部被关闭,read阻塞等待
写管道:
Ø 管道读端全部被关闭, 进程异常终止(也可使用捕捉SIGPIPE信号,使进程终止)
Ø 管道读端没有全部关闭:
u 管道已满,write阻塞。
u 管道未满,write将数据写入,并返回实际写入的字节数。
共享存储映射
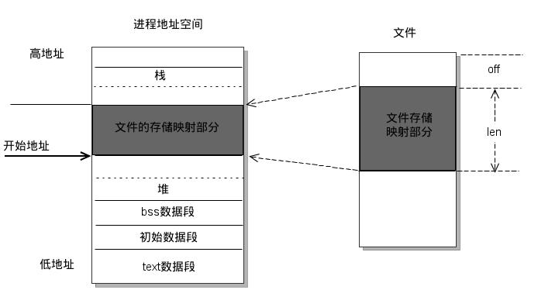
1 | //存储映射 |
匿名映射
就是mmap取掉最后一个fds
只能在父子进程之间进行
信号
信号的编号
POSIX.1对可靠信号例程进行了标准化。
信号四要素
编号 名称 时间 默认处理动作
查看详细信息man 7 signal
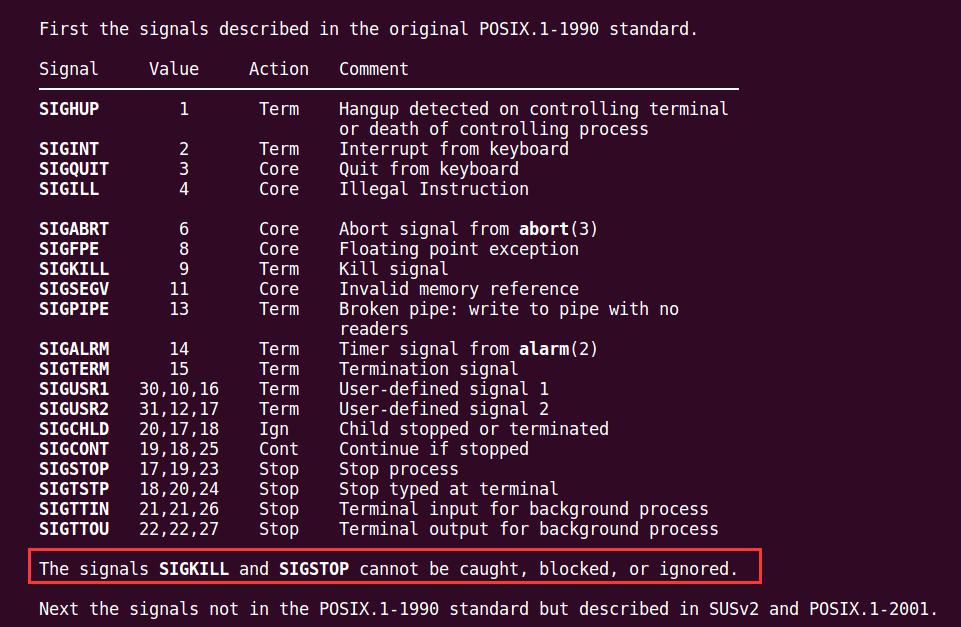
在标准信号中,有一些信号是有三个“Value”,第一个值通常对alpha和sparc架构有效,中间值针对x86、arm和其他架构,最后一个应用于mips架构。一个‘-’表示在对应架构上尚未定义该信号。
信号状态
阻塞信号 相当于黑名单
未决信号 相当于所有未接电话
信号产生后由于某些原因(主要是阻塞)不能抵达
据此可以分为未决信号集(可读可写)和阻塞信号集(只能读)
对于信号集的操作有固定的函数<signal.h>
1 |
|
1 |
|
设置屏蔽信号集
sigprocmask函数
设置之后这个集合里面的信号就不会去执行信号处理函数了,再发送这个信号就没有反应了,解除屏蔽之后,只能接收最后一次发送的这个信号
1 | int main() |
读取未决信号集
1 |
|
生成信号
kill
在main函数的父进程中 pid = fork(); kill(pid,15);;
raise
在main函数中自己给自己发送一个信号raise(15);也相当于kill(getpid(),15)
等价于 raise(SIGTERM)
abort
给自己发送一个异常中止编号为6的信号,直接abort();
alarm
设置闹钟
1 | int main() |
setitimer
捕获信号
捕获信号之后可以不再让信号中断停止,而是进行其他操作(信号处理函数)
sign函数
1 | // 信号处理函数 |
由于历史原因在不同版本的Unix和不同版本的Linux中可能有不同的行为。因此应该尽量避免使用它,取而代之使用sigaction函数。
sigaction
1 | #include <signal.h> |
注意一个语法
函数指针变量: void(*sa_handler)(int) 信号处理函数指针,在sigaction中用的act
函数指针类型: typedef void(*sa_handler)(int)相当于定义了一个以sa_handler为地址的函数变量,这个函数对应的return是coid(没有返回),输入参数是int。在signal函数中用的signal_handler
守护进程(线程)
在前台执行sleep 3000
在后台执行sleep 3000 &
用户只要远程登录服务器,就会在登录系统之后打开一个shell进程,用于执行这个shell进程的人机交互界面,就是终端
比如服务器只要启动,就会打开进程号为0的父进程,然后其他的进程通过fork这个进程,再加以修改,进行其他的动作

PPID 父进程
PID 进程组号
PGID 组进程
SID 会话ID
TTY 终端的名字 在终端李输入
tty可以查看当前终端的名字TGID 不知道
STAT 状态 未决 阻塞 到达
UID 不知道
TIME 时间
COMMAND 执行指令
会话
是进程组的集合
守护进程
在后台执行的进程,通常独立于控制终端存在,大部分进程如果执行的控制终端关闭进程也会跟着关闭
创建步骤:
- 创建子进程,父进程退出(必须)
2
3
4
5
if(pid>0)
{
exit(0);
}
- 所有工作在子进程中进行形式上脱离了控制终端,如果是正常的只有一个sleep()函数执行后会没有反应,只有sleep完之后才会出现
cc@itcast:~/test/pipe$,这样操作之后会接着出现cc@itcast:~/test/pipe$相当于后台进程,没有占用控制终端。但是只是形式上脱离,当关闭这个终端窗口时这个进程还是会死掉。
- 在子进程中创建新会话(必须)
- setsid()函数
- 使子进程完全独立出来,脱离控制
- 但终端窗口关掉,这个进程也不会收影响
- 改变当前目录为根目录(不是必须)
- chdir()函数
- 防止占用可卸载的文件系统
- 也可以换成其它路径
- 重设文件权限掩码(不是必须)
- umask()函数
- 防止继承的文件创建屏蔽字拒绝某些权限
- 增加守护进程灵活性
- 关闭文件描述符(不是必须)
2
3
close(1); STDOUT_FILENO
close(2); STDERR_FILENO
- 继承的打开文件不会用到,浪费系统资源,无法卸载
- 开始执行守护进程核心工作(必须)
守护进程退出处理程序模型
一般在终端中想要将时间写入txt文件
在终端中输入
date可以获取当前时间
输入
date >> txt就可以写入了
vim txt
所以在main函数只需要执行
system("date>>/tmp/txt.log");只是在main中执行即可,之前已经让父进程自动退出了,之前父子进程中是
2
3
4
5
6
7
8
{
}
if(pid == 0)//子进程
{
}现在是
2
3
4
5
6
7
8
9
{
exit(0);
}
while(1)
{
system("date>>/txt.log");
sleep(1);
}另一种获取时间的方式

动态的查看文件内容
tail -f /txt.log
线程
就是轻量级的进程
进程是CPU分配资源的最小单位,线程是操作系统调度的最小单位
线程:共享对方的地址空间
进程:复制对方的地址空间
线程号
线程创建
线程回收
线程退出
exit(0)是退出整个进程
return NULL pthread_exit(NULL) 退出线程
线程取消
pthread_cancel(tid)
一个线程栈的大小是8M
线程属性设置
线程同步
互斥:同一时刻一个资源只能被一个进程使用,两个任务不能同时运行,互斥具有唯一性和排他性
同步:运行必须按照规定的先后次序,比如A的运行依赖于B的运行结果,同步具有次序。
互斥锁
在访问共享资源(打印机)之前加锁,在访问共享资源之后解锁
如果加锁不成功就会阻塞,等待加锁成功
两种场景
打印机场景
第一个线程打印ABCDEF,第二个线程打印abcdef,两者混杂在一起,可能是AaBbcCDdEeFf这样
两个线程都对变量num = 100,num++,想得到的是102,
但是第一个线程读取内存中的num到寄存器里之后操作num++得到101再写回去,第二个线程也是读取num=100再num++得到101写回去,最后只是把101写了两次并没有得到102
步骤
在main函数之外定义一个pthread_t t变量
在main函数中初始化,如果没有特殊初始化函数的第二个变量一般为NULL
在线程回调函数加锁,操作,解锁
死锁
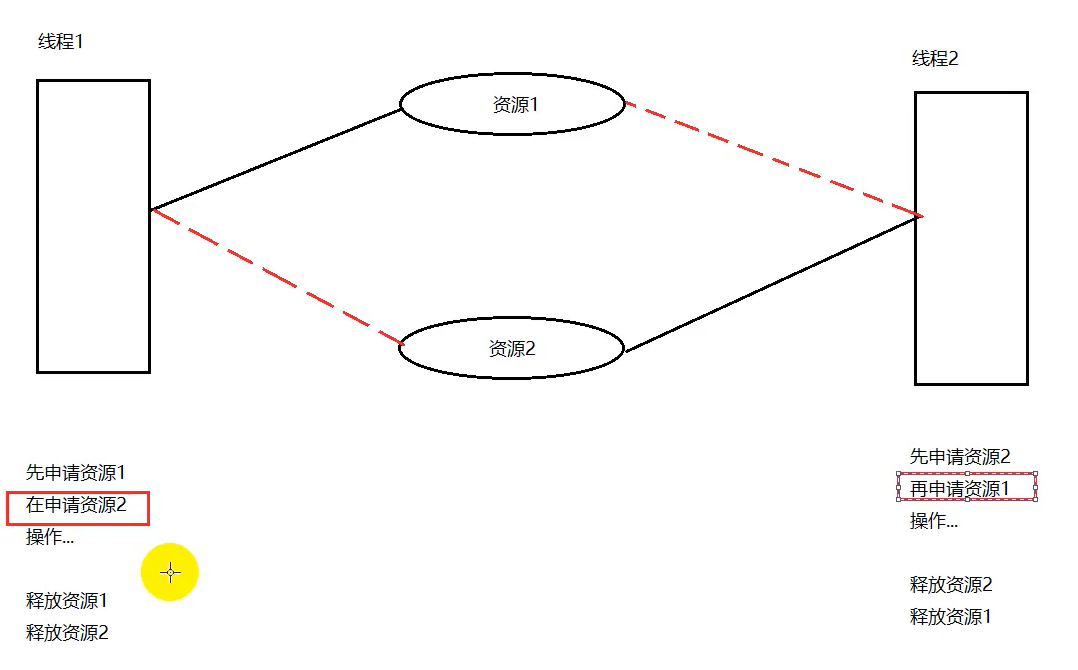
因为操作不当导致程序阻挡不能往下运行了,两个进程永远在互相等待
竞争不可抢占资源引起死锁
也就是我们说的第一种情况,而这都在等待对方占有的不可抢占的资源。
竞争可消耗资源引起死锁
有p1,p2,p3三个进程,p1向p2发送消息并接受p3发送的消息,p2向p3发送消息并接受p1的消息,p3向p1发送消息并接受p2的消息,如果设置是先接到消息后发送消息,则所有的消息都不能发送,这就造成死锁。
进程推进顺序不当引起死锁
有进程p1,p2,都需要资源A,B,本来可以p1运行A –> p1运行B –> p2运行A –> p2运行B,但是顺序换了,p1运行A时p2运行B,容易发生第一种死锁。互相抢占资源。
避免死锁:在申请超时的时候释放自己的资源,或者得到一个资源后操作完释放后再申请另一个资源,或者申请资源的顺序,都是先申请资源1再申请资源2
读写锁
银行取钱
两个人同时在一个账户取钱
一个程序加了读锁,其他程序可以加读锁但不能加写锁
一个程序加了写锁,其他程序读锁和写锁都不能加
条件变量
与互斥锁共同使用
1 |
|
生产者消费者体条件变量模型
1 |
|
信号量
用于进程和线程间的同步和互斥
用于管理线程和进程,统计正在运行的线程数,然后控制哪一个线程运行,哪一个线程阻塞
比如生产者消费者只能生成一个再消费一个,现在可以用信号量设置生产者最多只能生产四个,那么生产者生产4个不再生产,消费者消费一个之后生产者才能再生产,生产者生产几个消费者才能消费几个