语法
1. 变量的定义及其函数
基本变量(int,float,bool,str)
查看数据类型
1 | int a = 0; |
C++中好像不存在自动类型提升
1 | int i1 = 1; |
其他变量(string,vector,list)
auto
1 | auto it = cnt.find(fruits[left]); //这里自动推导迭代器 |
“auto”用于自动推导变量的类型。它允许编译器根据变量的初始化表达式来确定变量的类型,而无需显式指定类型。
字符串string
字符串删除
1 | string& erase(int pos, int n = npos);` //删除从Pos开始的n个字符 |
空字符串string()
子字符串
1 | int start = 0,end = 3; |
reverse
1 | reverse(s.begin(),s,end()); |
容器 vector
插入和删除
v.push_back(元素) v.pop_back(元素) v.emplace_back(元素)
v.erase(迭代器)
size大小
返回的是容器大小,但是容器最后一个变量的索引是
1 | nums.size() - 1 |
sort排序
对于容器v
1 | sort(v.begin(), v.end()); |
时间复杂度为O(nlogn)
初始化容器
声明一个简单int容器
vector
声明一个长度为5的容器
vector
声明一个长度为5,所有元素初始值为0的容器
vector
用已有的数组初始化容器,区间:[a,a+6)
int a[6]={5,6,2,0,9,4};
vector
用现有容器初始化一个容器
vector
vector
用迭代器初始化容器
vector
vector
把vector
1 | vector<int>& nums1; |
遍历容器
对于字符串t,遍历并计算每个元素出现的次数
1 | unordered_map <char,int> ori; |
其中c就是字符串t中的一个个元素
1 | for (vector<int>::iterator it = v.begin(); it != v.end(); it++) { |
其中it是v的迭代器,*it就是容器v中的一个个元素
另一种遍历方法:
1 | while (r < int(s.size())) { |
此时r是索引
还有一种
1 | for (auto it = mp.begin(); it != mp.end(); ++it) { |
这里的it是迭代器,而上面的c字符串t中的是一个个元素(字符)
都相当于,*it就是mp的元素了
1 | for(int i = 0;i<nums.size();i++) |
返回最后一个值
nums.back();
栈和队列
这两个都是数据类型,但本质上是以vectoe、list、deque写成的一种接口(容器适配器)
栈stack是先入后出
1 | stack<int> st; |
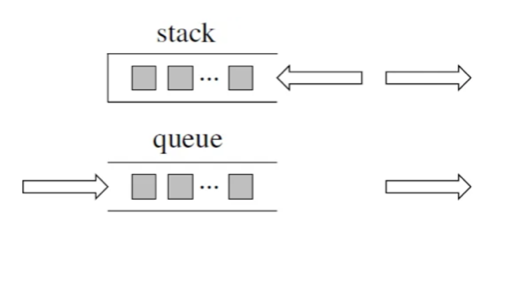
队列是先入先出
1 | queue<int> qu; |
双头队列
deque
que.front();
que.pop_front();
que.pop_back();
que.push_back();
查找
1 | string s; |
1 | vector<int> nums2; |
1 | map<int, int>m; |
键值对 pair
1 | pair<string, int> p2 = make_pair("Jerry", 10); |
pair构成map
1 | unordered_map<int, int> cnt |
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
注意:
- 对于
t中重复字符,我们寻找的子字符串中该字符数量必须不少于t中该字符数量。 - 如果
s中存在这样的子串,我们保证它是唯一的答案。
1 | class Solution { |
-
链表
定义:
1 | struct ListNode{ |
2. 运算符的使用
逻辑运算符
&&和&、||和| 跟 java一样
1 | void test07() |
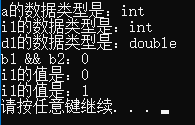
三目运算符
3. 函数的定义
在函数中调用容器
1 | int minSubArrayLen(int target, vector<int>& nums) { |
4. 结构
结构分为正常的前向引用结构,分支结构(if,switch)和循环结构
循环结构
for循环
是可以不加迭代的
一般是
for(①;②;④)
{
③
}
①初始化
②停止条件
③函数体
④迭代
①——>②——>③——>④——>②——>③——>④
可以
for(①;②;)
{
③
}
while循环语句
作用:满足循环条件,执行循环语句
语法: while(循环条件){ 循环语句 }
解释:==只要循环条件的结果为真,就执行循环语句==

算法
数组
二分法
双指针法
只要有两个指针就可以,不管是一个快指针一个慢指针,还是两个相对方向移动的指针
可以认为是把暴力解法的双层循环,外层循环为快指针,内层循环为慢指针
滑动窗口
可以认为是双指针法的变种
异或实现swap
a ^ a=0
a ^ 0=a
a ^ b=b ^ a
a ^= b;
b ^= a;
a ^= b;
1
2
3
解释
a=(a ^ b);
b=(a ^ b) ^ b=a ^ (b ^ b) = a ^ 0 = a;
a=(a ^ b) ^ a =(a ^ a) ^ b = 0 ^ b =b;
排序算法
\MyBlog\source_posts\刷Leecode时遗忘的C++\1712584347763.png)
https://www.acwing.com/solution/content/24716/
注意事项
1、我用 vector<vector<int>> dp(n+1,vector<int>(m+1,0));超时;尝试vector<vector<uint64_t>> dp(n+1,vector<uint64_t>(m+1,0));
不同的数据类型在内存消耗和计算速度上有所差异。
vector<vector<int>>使用的是int类型,即有符号整数。有符号整数的取值范围是有限的,通常为 -2^31 到 2^31-1 之间。当在动态规划等问题中使用int类型来存储中间结果时,可能会出现整数溢出的情况,导致结果不正确。而
vector<vector<uint64_t>>使用的是uint64_t类型,即无符号64位整数。无符号整数的取值范围是非负的,通常为 0 到 2^64-1 之间。使用无符号整数类型可以更好地处理较大的数值,避免溢出问题,从而得到正确的结果。由于
uint64_t类型可以表示更大的整数范围,可能会占用更多的内存空间。这也是为什么使用vector<vector<uint64_t>>可能会导致更高的内存消耗。但是,如果问题需要处理较大的数值或需要较大的计数范围,选择使用uint64_t类型是更合适的。因此,在你的情况下,使用
vector<vector<uint64_t>>帮助避免了整数溢出问题,从而得到了正确的结果。但请注意,使用更大的数据类型可能会增加内存消耗和计算时间,所以在选择数据类型时需要权衡内存和速度的要求。
2、测试样例通过但是提交不通过
最后的答案MOD 10e9+7试试